大文件上传相关
...大约 8 分钟
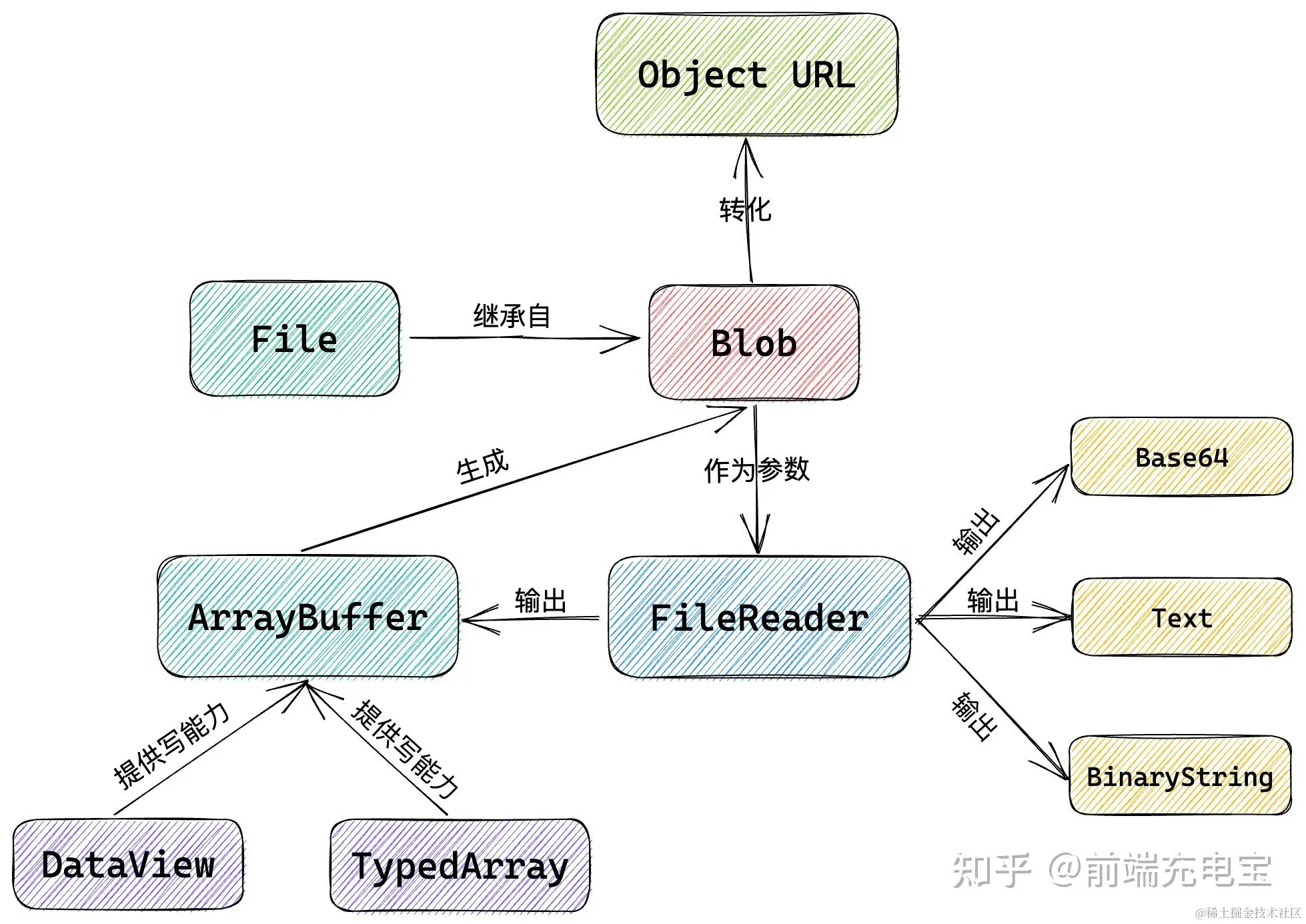
思维导图

大文件上传全部逻辑
读取文件(点击上传)
**文件分片 **
**计算hash值**
校验是否需要上传
分片上传 --上传参数里面提供一个当前分片和一个已经上传过的分片
参考
vue3 -大文件上传,切片上传,秒传&断点续传 前端vue3+vite
https://github.com/heyu3913/BigFileUpLoad
项目进入,分别进入client,server,npm i ; npm run dev
BigFileUpLoad
<script setup lang="ts">
import { ref } from 'vue'
import SparkMD5 from 'spark-md5'
// 1MB = 1024KB = 1024 * 1024B
const CHUNK_SIZE = 1024 * 1024
const fileName = ref<string>('')
const fileSize = ref<number>(0)
const fileHash = ref<string>('')
// 文件分片
const createFileChunks = (file: File) => {
let cur = 0
const chunks = []
while(cur < file.size) {
chunks.push(file.slice(cur, cur + CHUNK_SIZE))
cur += CHUNK_SIZE
}
return chunks
}
// 计算hash值
const calcuteHash = (chunks: Array<Blob>) => {
return new Promise(resolve => {
const targets: Blob[] = []
const spark = new SparkMD5.ArrayBuffer()
// 1. 第一个和最后一个切片全部参与计算
// 2. 中间的切片只有前两个字节、中间两个字节、后面两个字节参与计算
chunks.forEach((chunk, index) => {
if (index === 0 || index === chunks.length - 1) {
targets.push(chunk)
} else {
targets.push(chunk.slice(0, 2)) // 前两个字节
targets.push(chunk.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2)) // 中间两个字节
targets.push(chunk.slice(CHUNK_SIZE - 2, CHUNK_SIZE)) // 后面两个字节
}
})
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(new Blob(targets))
fileReader.onload = (e) => {
spark.append((e.target as FileReader).result);
resolve(spark.end());
}
})
}
// 合并请求
const mergeRequest = () => {
fetch('http://localhost:3000/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
fileHash: fileHash.value,
fileName: fileName.value,
size: CHUNK_SIZE
})
}).then(() => {
alert('合并成功!')
})
}
// 分片上传
const uploadChunks = async (chunks: Array<Blob>, existsChunks: string[]) => {
const data = chunks.map((chunk, index) => {
return {
fileName: fileName.value,
fileHash: fileHash.value,
chunkHash: fileHash.value + '-' + index,
chunk: chunk
}
})
const formDatas = data
.filter((item) => !existsChunks.includes(item.chunkHash))// 过滤掉已经上传过的
.map((item) => {// 把每一个分片转换成formdata
const formData = new FormData()
formData.append('fileName', item.fileName)
formData.append('fileHash', item.fileHash)
formData.append('chunkHash', item.chunkHash)
formData.append('chunk', item.chunk)
return formData
})
// [1,2,3,4,6,7]
const max = 6 // 最大并行请求数
const taskPool: any = [] // 请求队列
let index = 0
while(index < formDatas.length) {
const task = fetch('http://localhost:3000/upload', {
method: 'POST',
body: formDatas[index]
})
task.then(() => {
// 执行完后把当前任务从任务队列中删除
taskPool.splice(taskPool.findIndex((item: any) => item === task))
})
taskPool.push(task)// 加入任务队列
if (taskPool.length === max) {
await Promise.race(taskPool)// 等待任务队列中任意一个任务完成
}
index ++
}
await Promise.all(taskPool)
// 所有分片上传完成后,通知服务器可以合并了
mergeRequest()
}
/**
* 验证该文件是否需要上传,文件通过hash生成唯一,改名后也是不需要再上传的,也就相当于秒传
*/
const verifyUpload = async () => {
return fetch('http://127.0.0.1:3000/verify', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
fileName: fileName.value,
fileHash: fileHash.value
})
})
.then((response) => response.json())
.then((data) => {
return data; // data中包含对应的表示服务器上有没有该文件的查询结果
});
}
const handleUpload = async (e: Event) => {
// console.log((e.target as HTMLInputElement).files); // 伪数组
// 读取文件
const files = (e.target as HTMLInputElement).files
if (!files) return
// console.log(files[0]);
fileName.value = files[0].name
fileSize.value = files[0].size
// 文件分片
const chunks = createFileChunks(files[0])
// 计算hash值
const hash = await calcuteHash(chunks)
fileHash.value = hash as string
// console.log(hash);
// 校验是否需要上传
const { data } = await verifyUpload()
console.log(data);
if (!data.shouldUpload) {
alert('秒传成功')
return;
}
// 分片上传
uploadChunks(chunks, data.existsChunks)// data.existsChunks表示已经上传过的分片
}
</script>
<template>
<h1>大文件上传</h1>
<input @change="handleUpload" type="file">
</template>
<style scoped>
</style>const express = require('express');
const path = require('path');
const multiparty = require('multiparty');
const fse = require('fs-extra');
const cors = require("cors");
const bodyParser = require('body-parser');
const UPLOAD_DIR = path.resolve(__dirname, 'uploads')
const app = express();
// 提取文件后缀名
const extractExt = filename => {
return filename.slice(filename.lastIndexOf('.'), filename.length)
}
app.use(bodyParser.json());
app.use(cors());
app.post('/upload', function (req, res) {
const form = new multiparty.Form()
form.parse(req, async (err, fields, files) => {
const fileHash = fields['fileHash'][0]
const chunkHash = fields['chunkHash'][0]
// 临时存放切片的文件夹
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
// 如果目录不存在,则创建一个新的
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir)
}
// 如果存在,将所有的切片放到对应的目录里面
const oldPath = files['chunk'][0]['path']
await fse.move(oldPath, path.resolve(chunkDir, chunkHash))
res.status(200).json({
ok: true,
msg: '上传成功'
})
})
})
app.post('/merge', async function(req, res) {
const { fileHash, fileName, size } = req.body
// console.log(fileHash);
// console.log(fileName);
const filePath = path.resolve(UPLOAD_DIR, fileHash + extractExt(fileName))
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
if(fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
msg: '合并成功'
})
return;
}
if (!fse.existsSync(chunkDir)) {
res.status(410).json({
ok: true,
msg: '合并失败,请重新上传'
})
return;
}
const allChunks = await fse.readdir(chunkDir)
allChunks.sort((a, b) => {
return a.split('-')[1] - b.split('-')[1]
})
// console.log(filePath);
const list = allChunks.map((chunkPath, index) => {
return new Promise(resolve => {
const readSream = fse.createReadStream(path.resolve(chunkDir, chunkPath))
const writeSream = fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
readSream.on('end', async () => {
await fse.unlink(path.resolve(chunkDir, chunkPath))
resolve()
})
readSream.pipe(writeSream)
})
})
await Promise.all(list)
fse.rmdirSync(chunkDir)
res.status(200).json({
ok: true,
msg: '合并成功'
})
})
app.post('/verify', async function (req, res) {
const { fileHash, fileName } = req.body
const filePath = path.resolve(UPLOAD_DIR, fileHash + extractExt(fileName))
const chunkDir = path.resolve(UPLOAD_DIR, fileHash)
let allChunks = []
// 拿到之前已经上传过的分片
if (fse.existsSync(chunkDir)) {
allChunks = await fse.readdir(chunkDir)
}
if (fse.existsSync(filePath)) {
res.status(200).json({
ok: true,
data: {
shouldUpload: false
}
})
} else {
res.status(200).json({
ok: true,
data: {
shouldUpload: true,
existsChunks: allChunks
}
})
}
})
app.listen(3000, () => {
console.log('Server is running on port 3000');
});修改成原生js
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>大文件上传</title>
</head>
<body>
<h1>大文件上传</h1>
<input id="fileInput" type="file" onchange="handleUpload">
<script src="https://cdn.jsdelivr.net/npm/spark-md5@3.0.0"></script>
<script>
// 1MB = 1024KB = 1024 * 1024B
const CHUNK_SIZE = 1024 * 1024;
let fileName = '';
let fileSize = 0;
let fileHash = '';
// document.getElementById('fileInput').addEventListener('change', handleUpload);
//点击上传
async function handleUpload(e) {
const files = e.target.files;
if (!files) return;
fileName = files[0].name;
fileSize = files[0].size;
// 分片上传
const chunks = createFileChunks(files[0]);
// 计算hash值
fileHash = await calculateHash(chunks);
// 校验是否需要上传
const shouldUpload = await verifyUpload();
if (!shouldUpload.shouldUpload) {
alert('秒传成功');
return;
}
// 分片上传
uploadChunks(chunks, shouldUpload.existsChunks);
}
// 文件分片
function createFileChunks(file) {
let cur = 0;
const chunks = [];
while (cur < file.size) {
chunks.push(file.slice(cur, cur + CHUNK_SIZE));
cur += CHUNK_SIZE;
}
return chunks;
}
// 计算hash值
function calculateHash(chunks) {
return new Promise((resolve) => {
const targets = [];
const spark = new SparkMD5.ArrayBuffer();
chunks.forEach((chunk, index) => {
if (index === 0 || index === chunks.length - 1) {
targets.push(chunk);
} else {
targets.push(chunk.slice(0, 2)); // 前两个字节
targets.push(chunk.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2)); // 中间两个字节
targets.push(chunk.slice(CHUNK_SIZE - 2, CHUNK_SIZE)); // 后面两个字节
}
});
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(new Blob(targets));
fileReader.onload = (e) => {
spark.append((e.target.result));
resolve(spark.end());
};
});
}
//验证该文件是否需要上传,文件通过hash生成唯一,改名后也是不需要再上传的,也就相当于秒传
const verifyUpload = async () => {
return fetch('http://127.0.0.1:3000/verify', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
fileName: fileName.value,
fileHash: fileHash.value
})
})
.then((response) => response.json())
.then((data) => {
return data; // data中包含对应的表示服务器上有没有该文件的查询结果
});
}
// 分片上传
const uploadChunks = async (chunks, existsChunks) => {
const data = chunks.map((chunk, index) => {
return {
fileName: fileName.value,
fileHash: fileHash.value,
chunkHash: fileHash.value + '-' + index,
chunk: chunk
}
})
const formDatas = data
.filter((item) => !existsChunks.includes(item.chunkHash))// 过滤掉已经上传过的
.map((item) => {// 把每一个分片转换成formdata
const formData = new FormData()
formData.append('fileName', item.fileName)
formData.append('fileHash', item.fileHash)
formData.append('chunkHash', item.chunkHash)
formData.append('chunk', item.chunk)
return formData
})
// [1,2,3,4,6,7]
const max = 6 // 最大并行请求数
const taskPool = [] // 请求队列
let index = 0
while (index < formDatas.length) {
const task = fetch('http://localhost:3000/upload', {
method: 'POST',
body: formDatas[index]
})
task.then(() => {
// 执行完后把当前任务从任务队列中删除
taskPool.splice(taskPool.findIndex((item) => item === task))
})
taskPool.push(task)// 加入任务队列
if (taskPool.length === max) {
await Promise.race(taskPool)// 等待任务队列中任意一个任务完成
}
index++
}
await Promise.all(taskPool)
// 所有分片上传完成后,通知服务器可以合并了
mergeRequest()
}
// 合并请求
const mergeRequest = () => {
fetch('http://localhost:3000/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
fileHash: fileHash.value,
fileName: fileName.value,
size: CHUNK_SIZE
})
}).then(() => {
alert('合并成功!')
})
}
</script>
</body>
</html>逻辑
点击上传
分片上传
通过slice进行文件分片 -谷歌浏览器是六核,或者读取电脑内核来动态改变
通过spark-Md5计算hash 来生成唯一hash值,生成分别生成文件hash和切片hash,
通过FileReader读取文件携带着hash值并进行上传操作
这里就完成了基本的文件切片上传基本功能了
合并分片
然后上传完毕文件发送合并文件指令让后台合包
秒传
实现秒传只需要在文件上传之前请求接口验证一下文件是否存在。
拓展multiparty,fs-extra,spark-md5
multiparty、fs-extra和spark-md5是Node.js的三个不同的库,它们各自有不同的用途:
- multiparty:
multiparty是一个Node.js库,用于解析HTTP请求中的multipart/form-data格式,这通常用于上传文件。它允许你以一种相对简单的方式来处理HTML表单中的文件上传。
var multiparty = require('multiparty');
var http = require('http');
http.createServer(function(req, res){
var form = new multiparty.Form();
form.parse(req, function(err, fields, files){
// 'fields' contains non-file inputs
// 'files' contains files
});
}).listen(8080);- fs-extra:
fs-extra是一个扩展了Node.js内置的fs模块的库,提供了更多有用的方法,如mkdirs(递归创建目录)、copy(复制文件或目录)等。它使得文件系统操作更加方便。
var fs = require('fs-extra');
// 递归创建目录
fs.mkdirsSync('/tmp/a/b/c', function (err) {
if (err) console.error(err);
});
// 复制文件
fs.copy('/tmp/a', '/tmp/b', function (err) {
if (err) console.error(err);
});- spark-md5:
spark-md5是一个用于计算MD5哈希值的JavaScript库,它适用于Node.js和浏览器环境。它提供了一个简单的方式来生成文件或字符串的MD5摘要。
var sparkMD5 = require('spark-md5');
var fileContents = fs.readFileSync('example.txt', 'utf8');
var hash = sparkMD5.hash(fileContents);
console.log(hash);如果你想要在你的Node.js项目中使用这些库,你需要先安装它们。可以使用npm来安装:
npm install multiparty fs-extra spark-md5这将在你的node_modules目录下安装这些库,并在package.json文件中添加相应的依赖项。之后,你就可以通过require语句在你的代码中使用它们了。
赞助





