Agent基础入门实战教程(4):LangChain聊天机器人小练习
【写在前面】
1:本教程为本人学习agent的总结文档,均为手动筛选个人觉得重点的内容,也当做是一个笔记分享给想学习agent的佬友们,如有错误,请指正。
2:本人为前端转agent中,如有岗位可私,base:杭州。
上一篇导航
【写在前面】 1:本教程为本人学习agent的总结文档,均为手动筛选个人觉得重点的内容,也当做是一个笔记分享给想学习agent的佬友们,如有错误,请指正。 2:本人为前端转agent中,如有岗位可私,base:杭州。 上一篇导航 3.1 环境准备 环境 说明 langchain LangChain 主包,提供 Agent、Chain、模型初始化等常用入口,是开发 LangC…
上一节我们已经初步认识了langchain的基本用法,但是我们学习的都是一个一个知识点片段,如果不加以练习的话,会很容易忘记,所以这节课,我们一起来练习巩固一下。
1. 先准备好环境变量
from dotenv import load_dotenv
import os
load_dotenv(override=True)
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
model_name = os.getenv("MODEL_NAME", "gpt-5.4-mini")2. 初始化聊天模型
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model=model_name,
temperature=0,
api_key=api_key,
base_url=base_url,
)
print("模型初始化完成")3. 使用langchain创建Agent实例
from langchain.agents import create_agent
agent = create_agent(
model=llm,
tools=[],
system_prompt=(
"你叫小智,是一名乐于助人的智能助手。""请在对话中保持温和、有耐心的语气。""回答新手问题时,要尽量解释清楚,并适当举例。"
),
)
print("Agent 创建完成")前3步其实是我们在写langchain应用时,比较常见的固定初始化流程,可理解为前期准备工作。
4. 调用一次
result = agent.invoke({
"messages": [
{"role": "user", "content": "你好,你是谁?"}
]
})
final_message = result["messages"][-1]
print(final_message.content)5. 保存多轮对话
聊天机器人如何想要能连续对话,就需要保存历史信息。
下面先手动维护一个聊天列表
messages = []
messages.append({
"role": "user", "content": "我叫小明"
})
result = agent.invoke({"messages": messages})
reply = result["messages"][-1].content
print("小智:", reply)
messages.append({"role": "assistant", "content": reply})6. 流式输出
stream_messages = [
{"role": "user", "content": "请用三句话解释什么是 LangChain。"}
]
full_reply = ""print("小智:", end="", flush=True)
for part in agent.stream(
{"messages": stream_messages},
stream_mode="messages",
version="v2",
):
if part["type"] != "messages":
continue
token, metadata = part["data"]
if metadata.get("langgraph_node") != "model":
continue
if token.text:
print(token.text, end="", flush=True)
full_reply += token.text
print("\n\n完整回复:")
print(full_reply)上面6步,我们已经创建了单轮对话的聊天机器人,机器人的输出方式:流式输出和非流式输出我们都已经练习到了。但是我这里推荐大家一定要每一步都将结果打印一下,仔细看看langchain响应的结果的结构是咋样的。
7. 封装流式输出
上面的流式输出流程,我们也可以理解为是一个固定的流程,因为langchain返回的结构,我们如何封装聊天列表等,都是固定流程,所以我们可以将他封装成一个函数
def chat_once(user_input: str, messages: list[dict]) -> str:
messages.append({"role": "user", "content": user_input})
print("小智:", end="", flush=True)
full_reply = ""for part in agent.stream(
{"messages": messages},
stream_mode="messages",
version="v2",
):
if part["type"] != "messages":
continue
token, metadata = part["data"]
if metadata.get("langgraph_node") != "model":
continueif token.text:
print(token.text, end="", flush=True)
full_reply += token.text
print()
messages.append({"role": "assistant", "content": full_reply})
return full_reply8. 多轮对话
上面我们写好了单轮对话,那我们只要能将用户提问能够输入,然后加一个无限循环,那就是多轮对话了。
messages = []
print("输入 exit 或 quit 退出对话\n")
while True:
user_input = input("你:")
if user_input.lower() in {"exit", "quit"}:
print("对话结束,再见!")
breakif not user_input.strip():
print("请输入内容。")
continueprint(f"你:{user_input}")
chat_once(user_input, messages)
print("-" * 40)
# 避免历史消息无限增长。这里保留最近 100 条消息。
messages = messages[-100:]9. 测试
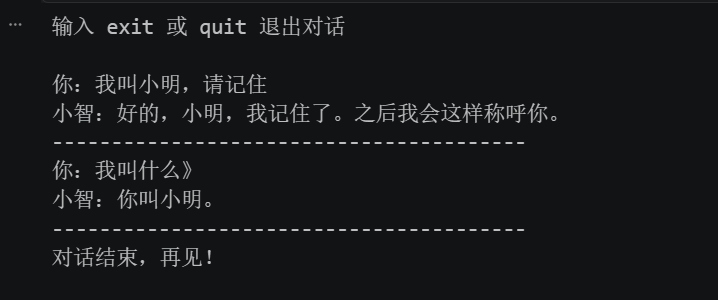
这是我本地运行后的结果,我先输入我叫小明,后续我再提问的时,AI已经能知道我的名字。这说明我们做的这个小机器人已经能拥有记忆了,这个记忆就是我们手动维护的聊天列表。
当然我们这个是一个最简单的聊天机器人,只简单维护了聊天列表。在真实的企业级的agent中,会围绕这个最小agent去扩展他的各方面的能力。列如:工具调用,长期记忆,知识库检索,权限控制等。
掌握这个最小版本之后,后面再学习复杂 Agent,就会更容易理解它们是怎么一步步扩展出来的。接下来我们将深入学习langchain,加油!
langchain小练习.zip (2.5 KB)





